
Although the gage reproducibility and repeatability (GR&R) study is a crucial tool in Six Sigma’s DMAIC (Define, Measure, Analyze, Improve, Control) toolset, it is not the most glamorous; mistakes in its execution are common among new Six Sigma practitioners. The standard for assessing if a gage is acceptable can vary significantly from organization to organization, but most focus on one of the following:
- A minimum number of distinct categories
- A maximum percent contribution of R&R variation to the overall study variation
However, use of a third metric – the category resolution of the gage – can help ensure a proper assessment of the gage and provide a more intuitive way to communicate gage results to colleagues unfamiliar with Six Sigma.
Proper Part Selection
To rely on either the number of distinct categories or the percent R&R contribution requires proper part selection for the study – based on the tolerance window. Selection of a group of parts too diverse will make the gage seem better than it is, while selection of a group of parts too similar can cause a good gage to be assessed as insufficient. To demonstrate these, consider two hypothetical gage R&R studies conducted by two new Six Sigma practitioners on separate processes for the fictional Liberty Weights Company.
A Tale of Two Facilities
Liberty Weights produces exercise weights with various targets. Recent regulations require their weights’ actual mass be within 1 lb. of the advertised weight. In order to ensure Liberty can adequately measure the produced weights and ensure compliance, gage R&R studies are conducted at their two production facilities – the original AoC facility and the new CoUS facility designed with improved equipment and processes. For the purposes of this case study, normally distributed data was generated using the standard deviations below.
| Table 1: Standard Deviations Used | ||
| Facility | StDev of Operator Measurement Bias | StDev of Device Measurement Error |
| AoC | 0.25 lbs. | 1.00 lbs. |
| CoUS | 0.10 lbs. | 0.10 lbs. |
Additionally for the purposes of this example, the CoUS facility is assumed to have a superior measurement device to the older AoC facility’s device, with substantially lower reproducibility and repeatability error. Liberty’s Six Sigma department requires a measurement system have both at least seven distinct categories and a percent R&R contribution of less than 10 percent.
AoC’s Gage R&R Study
At AoC, the Black Belt dives into his study. He chooses eight parts from the stock, grabbing two samples each of the Liberty Weight 30, 40, 50 and 70 lb. weights. He has each of these weights measured twice by three operators, in a randomized order. When he conducts his analysis, he is pleased to find his study shows a clearly acceptable gage by Liberty’s standards – with 20 distinct categories and an R&R contribution percentage of only 6.83 percent!
![Figure 1: Gage R&R (Analysis of Variance [ANOVA]) for Weight at AoC](https://www.isixsigma.com/wp-content/uploads/2018/07/Gage-RR-Analysis-of-Variance-ANOVA-for-Weight-at-AoC.gif)
| Table 2: AoC’s Gage R&R Results | |||
| Source | StdDev (SD) | Study Var (6 x SD) | % Study Var (% SD) |
| Total Gage R&R | 1.0936 | 6.5616 | 6.83 |
| Repeatability | 1.0413 | 6.2478 | 6.50 |
| Reproducibility | 0.3341 | 2.0049 | 2.09 |
| Operator | 0.3341 | 2.0049 | 2.09 |
| Part-to-part | 15.9826 | 95.8957 | 99.77 |
| Total Variation | 16.0200 | 96.1199 | 100.00 |
| Number of Distinct Categories = 20 | |||
AoC’s Issue
Unfortunately, a closer look at the data tells a less favorable story. The Black Belt has fallen into a common trap – wanting to assess the gage across the full context of the product line. Here, the parts chosen encompass too large of a range. Instead of answering the question, “Can I distinguish between bad parts and good parts?” the Black Belt has instead answered the question, “Can I distinguish between our different products?” Unless his work is checked carefully, there will be unwarranted confidence in AoC’s gage.
Consideration of an additional metric can provide the Black Belt a clue to his error – the resolution of those distinct categories. By determining the range of the parts checked (in this case, the parts’ actual weights range from 29.29 lbs. to 70.42 lbs., for a range of 41.13 lbs.) and dividing by the 20 distinct categories, a category resolution of 2.06 lbs. can be calculated.
That is, without taking repeated measurements, the gage can reliably differentiate between parts only if the weights differ between more than 2.06 lbs. This is clearly a problem – trying to use this gage to assess if weights are within 1 lb. of target will result in a lot of good products being incorrectly categorized as defective. Similarly, bad products may often be considered within specification.
CoUS’s Gage R&R Study
Separately, the second Black Belt begins a gage R&R at the CoUS facility. Aware of the dangers of choosing too wide of a spread, she chooses all eight parts randomly from their inventory of 50 lb. weights. Other than part selection, the gage R&R is run using the same method as in the first example, with weights measured twice by three operators, in a randomized order. This time, the gage R&R results are far short of Liberty’s standards, with only two distinct categories and a Gage R&R contribution of 56.63 percent.
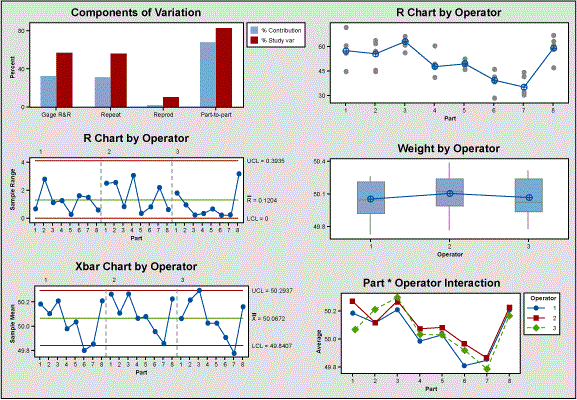
| Table 3: CoUS’s Gage R&R Results | |||
| Source | StdDev (SD) | Study Var (6 x SD) | % Study Var (% SD) |
| Total Gage R&R | 0.098587 | 0.59152 | 56.63 |
| Repeatability | 0.096988 | 0.58193 | 55.71 |
| Reproducibility | 0.017685 | 0.10611 | 10.16 |
| Operator | 0.017685 | 0.10611 | 10.16 |
| Part-to-part | 0.143482 | 0.86089 | 82.42 |
| Total Variation | 0.174088 | 1.04453 | 100.00 |
| Number of Distinct Categories = 2 | |||
CoUS’s Issue
The AoC gage appeared far better than reality at first glance because the part selection was too broad. Now the CoUS gage appears far worse than reality, because the part selection was too narrow. The range of actual parts coming off of the CoUS production line is smaller than the tolerance window the measurement gage needs to assess.
Here, too, a consideration of the category resolution can help correct this problem. In the CoUS study, the range of parts is merely 0.42 lbs. (maximum weight of 50.25 lbs. and minimum weight of 49.83 lbs.). Even though there are only two distinct categories, the smaller range gives a category resolution of 0.21 lbs.
In actuality, the CoUS gage is far more capable than the AoC gage.
Conclusion
Both studies came to incorrect conclusions stemming from improper part selection – failures that often occur in actual practice. Selecting the proper range of parts is often an unintuitive process for Six Sigma practitioners who are accustomed to keeping the entire process in mind, and if actual specification limits do not exist, neither does an easy-to-use tolerance window. Using category resolution to determine the “so what” of the measurement gage provides a more robust metric to errors in part selection. Expanding the range of parts expands the number of distinct categories, but the category resolution remains the same.
Finally, the use of category resolution also assists with communicating the gage’s capability to less statistically-savvy persons. While explaining “the gage R&R contributed to 13 percent of the study variation” will produce blank stares, “This device is accurate within a fifth of a pound” is easier for the uninitiated to understand. Putting the results into a more practical metric will help ensure your measurement systems are assessed appropriately.