
 A leading environmental services company applied the DMAIC (Define, Measure, Analyze, Improve, Control) methodology to improve the availability of an internal software system. The goal was to reduce system downtime (the time that the software application is not available for users) and reduce defect resolution time (the time it takes to fix a software defect once it is reported), thereby increasing return on investment (ROI) and user satisfaction.
A leading environmental services company applied the DMAIC (Define, Measure, Analyze, Improve, Control) methodology to improve the availability of an internal software system. The goal was to reduce system downtime (the time that the software application is not available for users) and reduce defect resolution time (the time it takes to fix a software defect once it is reported), thereby increasing return on investment (ROI) and user satisfaction.
Business Background
The environmental services company provides collection, processing, recycling, and disposal of hazardous and non-hazardous materials for industrial and automotive customers. The company has branches all over the United States. The branches carry out services for customers in their respective territories; each branch completes several services for different customers on a single day.
For a given day, the branch determines the order in which the services are to be executed. This order of execution is based on customer preferences, pre-determined time windows and the availability of resources (e.g., drum capacity) for services to be performed.
The Route Management team uses a transport management system (TMS) to optimize routing services between customers in a territory. The TMS determines the most efficient route between customers based on factors such as distances between locations and time taken for services to be performed, in addition to the pre-determined parameters mentioned above. The service representatives obtain service routes from the TMS, complete their assigned services and update the TMS. This update process is critical in ensuring that the “completed services” data is in sync with the “planned services” data in the system.
The branch personnel and service representatives are the principal users of the system. The Branch Operations Support Team (Branch Ops) provides functional expertise and business rules. The Branch Ops team is the liaison between the branch personnel and the Route Management Information Technology (IT) Group, which is responsible for system maintenance and technical support.
If the branch personnel encounter an issue with the TMS software application, they submit a defect report through the defect-tracking system. Defects can be:
- Software application related (e.g., system downtime – cannot access system, cannot optimize routes, user-interface screen is locked).
- Data related (e.g., branch addresses incorrect, service orders not correctly loaded for a given branch, service group has incorrect volume).
- An enhancement request.
Concerns About the TMS
The branch employees and field personnel had concerns about the TMS. The TMS seemed to slow down and stall at random times throughout the day; the system then experienced downtime before it was available again for the field personnel to complete their tasks. The users expected – and needed – the system to be responsive and nimble since it managed real-time data. The users also needed quicker resolution times for reported defects.
A process improvement team was deployed to increase user satisfaction and ROI by improving the availability of the TMS by:
- Minimizing system downtime of software application.
- Reducing the resolution time of reported software defects.
Define
As primary users of the system, the service representatives and the field forces are most affected by system unavailability and downtime. The Branch Ops team plays an important role in resolving functional issues quickly and informing IT about technical defects. They communicate with the field personnel regularly so are aware of commonly occurring issues and required enhancements. Together, IT, Branch Ops and service representatives defined the problem areas as the slowness of the TMS and poor system availability, and the length of time to fix reported issues.
The goal of this project was to aim for 99 percent system availability and to reduce resolution time by at least 50 percent.
Measure
Process mapping was used to characterize the “current” process as shown in Figure 1 below.
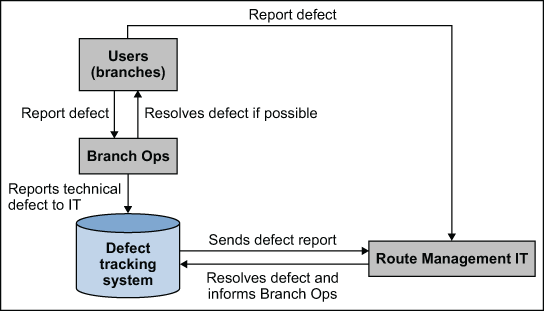
Branch personnel report defects in a defect-tracking system, which then are routed through Branch Ops to IT. Sometimes, the defect requests are routed directly to IT, bypassing the Branch Ops group. This is a problem because:
- In some cases, the issue is the result of incomplete user training or missing functional knowledge. The Branch Ops team has excellent functional and business knowledge and can easily resolve many issues, greatly reducing resolution time. In such cases, IT does not need to be involved.
- Some of the tickets coming directly from the end users are ambiguous or do not contain all the information that IT requires to resolve the issue. Time is wasted as IT contacts the user and gathers more information, before being able to process the request and resolve the issue. The Branch Ops team includes subject matter experts who ensure that defect reports contain all the information required for resolution.
Metrics
Metrics were selected for tracking process improvement.
| Issue | Metric |
| Poor system availability | The number of reports of system unavailability and slowdown. |
| Resolution time of defects | The time between the initial reporting of a defect and the resolution of the defect. |
To narrow the project’s focus area, the defects reported in the previous year were analyzed and categorized, as shown in Figure 2.
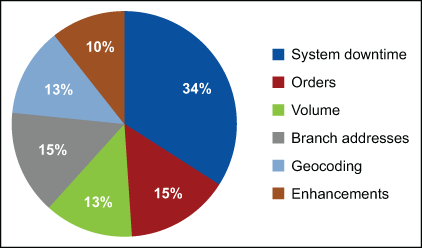
Poor system availability, or downtime, accounted for approximately 34 percent of all reported defects, making it the primary issue facing field personnel.
Measure
Poor System Availability
The system slowed down or stalled at random times throughout the workweek. Field personnel were unable to update their tasks or sync data with the host system.
In order to trace the root cause of these slow and stopped periods, message queues and server logs were analyzed. SQL traces (a way to record information about a software program’s execution) were run to see if there were conflicting queries or deadlocks, which could cause the incoming user requests to queue up. No pattern was uncovered.
The field personnel performed their work throughout the work day, nationwide. Due to the different time zones across the country, server downtime initially seemed to fluctuate randomly throughout the day. However, quantitative analysis of the reporting times of the defects seemed to suggest that the system availability was poor during the early half of the week and also toward the end of the work day, when a large number of users logged in to update their records. Nearly 75 percent of reports of system downtime came within the first three days of the week. Of these, more than 50 percent were reported in the mornings, at the start of the work day in the respective time zones.
Resolution Time of Defects
The time elapsed between reporting a defect and resolving it was measured. The average resolution time of incidents was approximately 20 minutes. Since the system managed real-time data, this length of time was unacceptably long for field personnel. The elapsed time needed to be halved – the desired time for defect resolution was 10 minutes.
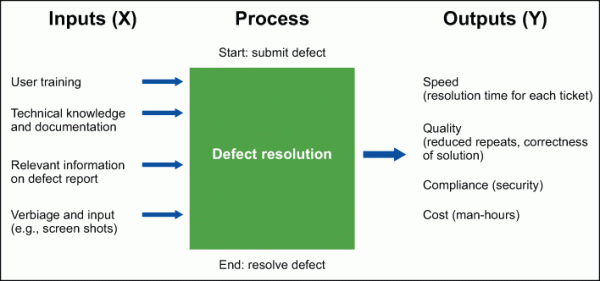
The input-process-output (IPO) tool was used to winnow down the factors that affect the resolution time of defects. That resulting list is the Inputs in Figure 3 below.
Analyze
Poor System Availability
Poor system availability during peak times suggested that the TMS was not able to balance the large volume of transactions occurring at that time. The simplistic round-robin domain name system load balancing that was already in use was not sufficient to ensure that the system was available at all times.
It was suggested that implementing a more sophisticated load-balancing technique between the servers may help to reduce the load on the existing servers, improve system stability and prevent user requests from getting bottlenecked. This more capable system, however, was complicated to set up, required external vendor support, was more expensive, required a license and more. Making the change was a significant expense, requiring time to install the software and train its employees to keep it running.
Several rounds of discussion were held between Branch Ops, infrastructure and the IT teams. Detailed documentation and quantitative analysis of system downtimes ensured that the decision to implement load-balancing for the TMS was escalated and prioritized.
Resolution Time of Defects
Slow response times were addressed with a 5 Whys analysis, which revealed the following issues as causes for delays:
- The go-between Branch Ops group had functional expertise but did not have technical knowledge or access rights to resolve issues in the TMS.
- Some incidents were routed directly to IT without being vetted by the Branch Ops group. These defects often had incomplete information. There were delays as the missing information was collected and IT was in a position to resolve the issue.
- The wording and input formats (e.g., screen shots) of the defects were not reported in a standard manner. Time was wasted as IT team members had to understand the issue before gathering relevant information and resolving the problem.
Improve
Poor System Availability
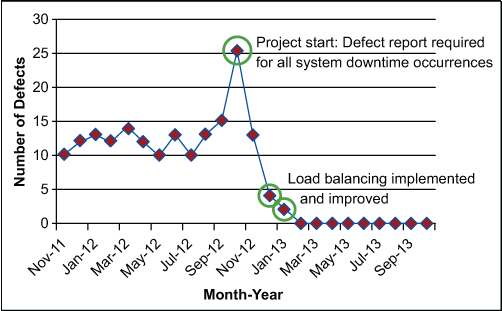
The more robust load balancing system was implemented among the TMS servers. The recovery process of servers was automated so that response time was almost instantaneous. This was an enormous improvement over the current situation for defect resolution times.
The requests to the servers could be processed in the order in which they were received. The stability and availability of the system improved tremendously and downtime was reduced from an average of 20 minutes to less than one minute.
Resolution Time of Defects
Several steps were taken to reduce the resolution time of reported software issues.
- Defect categorization: The issues reported by Branch Ops and field personnel were analyzed and categorized. Commonly occurring issues in the TMS were identified. User training was provided where needed.
- Branch Ops empowerment:
- Technical knowledge and documentation. Solutions to commonly occurring issues (such as geocoding issues or time lapses in updates) were documented; the documentation was provided to the Branch Ops group. Branch Ops is no longer dependent on IT to resolve common TMS issues. Most issues involving user training and user errors are now quickly resolved by Branch Ops.
- Increased system access. Key personnel of the Branch Ops group were given increased privileges in the TMS environment. Branch Ops personnel could explore the system at their convenience and suggest enhancements.
- Vetting of defect reports. All defects reports were routed exclusively through Branch Ops and common issues were quickly resolved. Defects involving technical issues were assigned to IT, but all reports were first vetted by Branch Ops; care was taken to ensure that reports contained all relevant information that would be required by IT to resolve the issues.
- Input and verbiage: Verbiage and input format was standardized. The level of ambiguity in the defect reports reduced drastically. IT could identify and isolate the issues quickly and move to resolve them promptly.
These simple procedures expedited the speed of defect resolution.
- Load balancing and automatic server restart reduced the resolution time for server downtime issues, from 20 minute to under a minute.
- The new load balancing software greatly improved the stability of the transport management system. Defects reporting data inconsistency reduced by 80 percent.
- Knowledge base documents were developed for commonly occurring issues and user training was provided where required. Resolution time for such issues was reduced by more than 50 percent.
- All tickets coming to IT had all the required information on them, and were accompanied by screen shots. There was no time wasted in contacting the user and gathering important information. This expedited the resolution process by 20 percent.
The Branch Ops group was empowered and readily took ownership of the routing data and the TMS. IT could focus time and resources on resolving technical issues and implementing enhancements.
Control
Poor System Availability
After implementing the new load balancing technique, the number of reports of system downtime was carefully monitored. Server-scheduled tasks were executed on a timely basis to proactively prevent the occurrence of server downtime.
Resolution Time of Defects
The resolution time of defects was monitored. The nature of reported issues assigned to IT and the verbiage of the issue was monitored. Issues within the realm of Branch Ops were reassigned to them allowing IT to focus solely on the more challenging and less routine technical issues.
Outcome
These simple steps increased the availability and reliability of the TMS. Productivity of the system greatly increased. There was a 98 percent decrease in reports of system downtime. User satisfaction and acceptance of the TMS increased tremendously.
As a result of this project, branch and field personnel no longer worry about system availability and data inconsistency; instead, they can focus on their jobs. The Branch Ops team is eager to exercise its new-found access rights and further explore, and help enhance, the TMS.
With these successes, the morale of the entire Route Management team has improved. Company personnel are energized to find ways to leverage the TMS and to further improve truck route optimization and efficiency.