
Key Points
- You can determine the Sigma level of your production by looking at the customer complaints given to your organization.
- If you aren’t conducting quality inspections, this can be a way to see just how your production is faring.
- The calculation performed is similar in scope to how you’d normally determine your production’s Sigma level.
At the beginning of a deployment, many companies set a goal of 3.4 defects per million opportunities (DPMO) using Six Sigma quality concepts in production and later extend this concept to other operational areas.
Fewer companies, however, have extended Six Sigma from a manufacturing application to manage customer satisfaction or customer complaints. However, it is possible to measure the sigma level of customer complaints, and this information can be valuable when making improvements in that area.
Putting Customer Complaint Data to Use
To determine the sigma level of customer complaints, an organization should use actual customer complaint data recorded by the sales personnel rather than data from customer surveys (Figure I). Six Sigma concepts depend more on fact-based data rather than simply opinion-based data.
Further, there is a need to go beyond the calculation of the percentage of customers who are dissatisfied to determine the sigma level of customer complaints. Through the process of determining the sigma level of complaints, practitioners will find the degree of customer satisfaction and customer retention, which help make up business excellence.
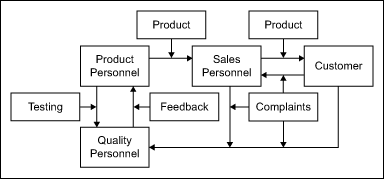
Compiling the Necessary Information
For illustration of this concept, consider the case where Company A manufactures various products in the form of rolls of certain a width. The area of each roll is calculated in square meters. The packing pattern of these rolls varies as they are converted into various sizes in the form of sheets, as per market requirements.
Although the converted sheets of the product are packed in boxes and sold, accounting is done in terms of area in square meters. That is, when a box of units is involved in a complaint, the actual area in square meters of material in the box that is involved in the complaint is taken into consideration rather than considering it as a single complaint. This is because the quantum of units involved in complaints per packing pattern varies.
Weekly and monthly reports on customer complaints received either from sales personnel or directly from customers are prepared by the quality assurance department and the reports are sent as product performance feedback to the concerned production department for future improvements. Annual reports are compiled on the overall complaints received in a particular year. These reports include the total number of complaints and the total area of complaints (the sum of the areas in square meters per complaint).
The usual practice is to compute the percentage of complaints against total sales of the product in the specified period, but this feedback fails to reflect the number of actual complainers and the number of possible complainers. It is simple to compute the sigma level of the complaints for the percentages, but neither the percentage nor sigma level of the number of actual complainers to the number of possible complainers (opportunities) is possible. It may be noted that the number of possible complainers is nothing but the customers who have the opportunity to raise complaints after the use of the product.
Is This Different From Using Data from Inspections?
On the surface, not really. Your data points might come from different sources, but the overall concept remains the same. As such, if you’re already accustomed to calculating your Sigma from something like inspection data, this should be a walk in the park.
Introducing the Seven-step Method
There is a seven-step method (Table I) that helps make meaningful analyses of the complaints data, which can provide critical information to practitioners. Necessary complaints data, such as several complaints received, the total area of complaints in square meters, and the total area of sales in square meters, is collected over a year. Then the sigma level of the number of actual complainers to the number of possible complainers in each year is determined using the seven-step procedure.
| Table 1: Seven-step Procedure for Finding Sigma Level of Customer Complaints | ||
| Step | Procedure | Notation |
| 1 | Obtain from records the actual number of complaints. (Note that each complaint has Xi (i = 1, 2, … , N1) square meters of defective area) | N1 (actual complainers) |
| 2 | Obtain the area of N1 complaints | A1 = E Xi Sq. m. |
| 3 | Find the average area per complaint | A2 = A1 / N1 Sq. m. |
| 4 | Obtain from the records the total area of sales in square meters during the year | A3 Sq. m. |
| 5 | Find the total number of possible complaints (possible complainers) | N2 = A3 / A2 (opportunities) |
| 6 | Find the total possible number of complaints per million opportunities (CPMO) | N3 = N1 / N2 X 1,000,000 |
| 7 | Obtain the sigma level against N3 | k |
One may observe in the seven-step procedure that A1 / A3 is numerically equal to N3 = N1 / N2. This is due to the nature of the mathematical development of N3. The interpretation is the purpose of using this method. The objective is to determine the sigma level of the actual number of complaints received and not the sigma level of the number of units involved in the complaint.
A Six Sigma organization always considers customer retention, in addition to reducing the number of units involved in the complaints. The organization knows that a single complaint of a large quantity is far better than as many complaints (complainers) of the same or smaller quantity. The latter is more dangerous because it is infectious.
Therefore, with the straightforward calculation of A1 / A3, the sigma level is interpreted as the sigma level of the area of units received as complaints relative to the area of units sold. Although N3 gives the same sigma level, it is interpreted as the sigma level of the number of actual complaints received relative to the number of possible complaints.
In addition, as the procedure sequentially goes through all steps, it provides useful information regarding the average number of units involved per complainer (Step 3 in Table 1) and the total number of possible complainers or opportunities (Step 5 in Table 1). Such information is essential in a situation where the number of units involved per packing pattern varies from complaint to complaint (see the assumption in Step 1 in Table 1) and the actual size of the population of possible complainers is not known.
As quality improves, the number of complainers will reduce, and hence the number of possible customers will increase (wider customer base) in the marketplace. As a result, the company can experience a higher sigma level and excellent customer retention (Figure 2).
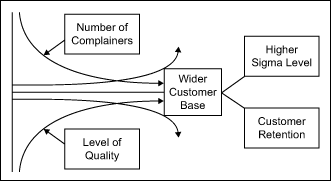
Seven-step System in Action
Two examples help illustrate the meaningful analyses of complaints data from a practitioner’s point of view using the seven-step method.
1. Manufacturing Case
Company A obtains the following details for a particular year:
N1 = 929 (actual number of complainers)
A1 =23,090.96 Sq.m.
A2 = A1 / N1 = 23,090.96 / 929 = 24.869 Sq.m.
A3 = 15,446,000 Sq.m.
N2 = 15,446,000 / 24.86 = 621,319 (possible number of complainers or opportunities)
N3 = (929 / 621,319) X 1,000,000 = 1,495 CPMO (complainers per million opportunities)
This corresponds to the sigma level k = 4.47.
It may be noted that, if units are produced where area in square meter conversion is not necessary, the sigma level easily can be calculated by making a simple change in the proposed seven-step procedure. Here, Xi is taken as the number of defective units per complaint instead of the area in square meters per complaint. The method can be used to determine the sigma quality level, even if the units are packed in bundles of many boxes and complaints are accounted for in the number of bundles per complaint or in any other form, as illustrated in Example 2.
2. Non-manufacturing Case
The proposed method is also suitable for Six Sigma analysis of customer complaints data in non-manufacturing settings. For example, at a restaurant recently, two groups were being served: my family with three people and another group of five people. Near the exit door inside the restaurant, there was a bell with a display saying, “If you are satisfied with our service, please ring the bell.” A group that does not ring the bell means there is at least one complaining customer, depending on the size of the dining group.
In this case, if both the groups register a complaint, then the number of complaints is only two, but the possible number of complaints is 3 + 5 = 8. On request, the restaurant provided complaints data for a particular year, for which the sigma level is obtained as follows using the seven-step procedure:
Total number of complaints: N1 = 32 groups
Number of customers involved in the complaints: A1 = 250 persons
Average number of customers per complaint: A2 = A1 / N1 = 250 / 32 = 7.81 persons
Total number of customers visited in the year: A3 = 135,000 persons
Total number of possible complaints: N2 = 135,000 / 7.81 = 17,285 groups (Opportunities)
Possible number of complaints per million customers: N3 = (32 / 17,285) X 1,000,000 = 1,851 CPMO
This corresponds to the sigma level k = 4.40.
Both examples show that quality practitioners would miss critical information from complaints data if they simply went by percentages. Particularly, the total number of possible complainers throws light on the status of the customer base, retention, and the sigma quality level of CPMO.
Other Useful Tools and Concepts
Need some other tips and tricks to get things rolling? You might want to take a closer look at how to readily handle process capability analysis. You’re making products to meet your customer expectations, and this guide covers quite a bit of legwork you can do to guarantee it.
Additionally, did you know you can calculate your capability indices with just a single specification? You can view our guide on the subject to get to grips with this simple and effective method.
Reveal the Degree of Customer Satisfaction
Customer satisfaction, wider customer base, and customer retention are key aspects of business excellence. Although customer survey data is often used to determine the degree of customer satisfaction, it is worthwhile to consider the actual complaints data to calculate the number of actual complainers and the number of possible complainers. The minimum number of complainers relative to the customer base reveals the degree of customer satisfaction and customer retention.
Six Sigma practitioners always prefer to know the outcomes of their project implementations and overall organizational performance in terms of Sigma quality level. Using the seven-step method, practitioners can determine the sigma quality level of customer complaints and fine-tune improvement activities.