
© Ground Picture/Shutterstock.com
Key Points
- Kappa is a quantitative means of measuring qualitative data.
- It is a simple calculation and readily allows you to see the accuracy of your measurements.
- It works with ordered data as well as boolean data.
The measurement system for attribute data (type of defect, categories, survey rankings, etc.) requires a different analysis than continuous data (time, length, weight, etc.).
For continuous data, you would use Measurement System Analysis or Gage R&R to judge the capability of your measurement system to give you reliable and believable data.
An Attribute Agreement Analysis relying on Kappa is used for the same purpose but for attribute data. This article will describe the calculations and interpretation of Kappa along with its benefits and best practices.
What Is Kappa?
Kappa measures the degree of agreement between multiple people making qualitative judgments about an attribute measure.
As an example, let’s say you have three people making a judgment on the quality of a customer’s phone call. Each rater can assign a good or bad value to each call. To have any confidence in the rating results, all three raters should agree with each other on the value assigned to each call (reproducibility). Plus, if the call is recorded and listened to again, each rater should agree with him/herself the second time around (repeatability).
The Kappa statistic tells you whether your measurement system is better than random chance. If there is significant agreement, the ratings are probably accurate. If agreement is poor, you might question the usefulness of your measurement system.
Kappa is the ratio of the proportion of times the raters agree (adjusted for agreement by chance) to the maximum proportion of times the raters could have agreed (adjusted for agreement by chance). The formula is:
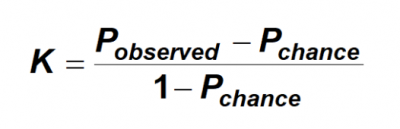
P observed is the sum of the proportions when both raters agree something is good plus when both raters agree something is bad. P chance is the proportion of agreements expected by chance = (proportion rater A says good x the proportion rater B says good) + (proportion rater A says bad x the proportion B says bad).
Putting It Into Action
Using the following sample set of data for our three raters listening to 20 calls twice, let’s see how to calculate Kappa for rater A. This calculation will be looking at repeatability, or the ability of rater A to be consistent in their rating. We would use the same method for calculating Kappa for raters B and C.
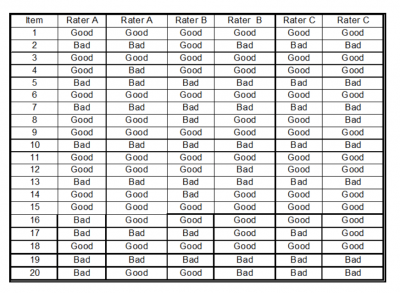
The first step is to create a summary table of the results.
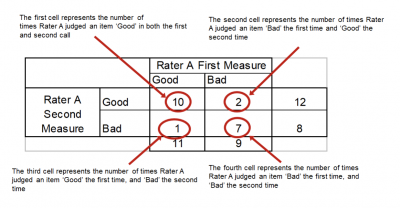
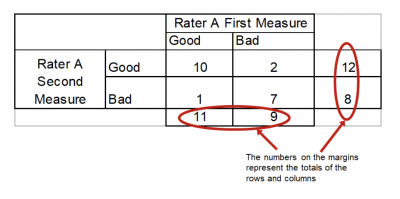
Step 2 is to create a contingency table of probabilities.
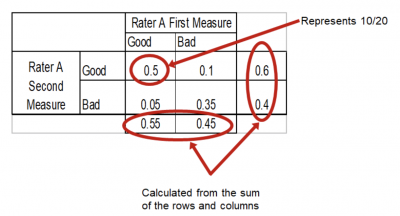
Step 3 is to do the calculations.

A similar process would be followed for calculating the within Kappas for raters B and C, and the between Kappa for all the raters. If repeatability for raters is poor, then reproducibility is meaningless.
The interpretation of the Kappa value is pretty simple. Kappa values range from –1 to +1. The higher the Kappa, the stronger the agreement and the more reliable your measurement system is.
- When Kappa = 1, perfect agreement exists
- If Kappa = 0, the agreement is the same as would be expected by chance
- When Kappa < 0, the agreement is weaker than expected by chance; this rarely occurs
Common practice suggests that a Kappa value of at least 0.70-0.75 indicates good agreement, while you would like to see values such as 0.90.
For the example above, the Kappa is 0.693, which is less than you would like to see, but is high enough to warrant further investigation and improvement of the measurement system. In most cases, improving the operational definition of the attribute will help improve the overall Kappa score.
Accuracy Is Key
So, we’ve covered the calculation portion of Kappa, but why does it matter in your production pipeline? Accuracy and precision in production are crucial to continual success in your organization. Kappa provides a way to verify the accuracy and precision of your processes without the need for more complicated tests and analysis.
Benefits of Kappa
Having a quantitative measurement of the quality of your measurement system brings several benefits. Here are a few.
Quantitative Value for Measurement System Performance
High or low values of Kappa provide a relative quantitative measure for determining if the data from your measurement system can be believed and trusted.
Simple Calculation
The four primary mathematical operations of adding, subtracting, multiplying, and dividing are the extent of math skills necessary for calculating Kappa.
Statistical Significance
An acceptable value for Kappa has been suggested to be around 0.70-0.75. Most statistical software will provide a p-value for the Kappa to indicate whether it is statistically significant.
Why Is Kappa Important to Understand?
Calculations and interpretation of Kappa are important if you want to understand the validity of your measurement system.
Attribute Agreement Analysis vs. Gage R&R
Attribute Agreement Analysis is used for attribute data, while Gage R&R is used for continuous data. If you can convert your attribute data to some form of continuous data, Gage R&R is a more powerful tool for measurement system analysis.
Most Common Measure of Intra- and Inter-rater Reliability
If you can’t agree with yourself when rating an attribute, you can’t agree with other raters. In other words, in the absence of repeatability, there can be no reproducibility. On the other hand, repeatability does not guarantee reproducibility. All raters are consistent with themselves but can’t agree. These are separate issues of a measurement system.
Works the Same for Ordinal Data as Binary Data
Whether your attribute is of the form good/bad or on a scale of 1-5, the technique, calculations, and interpretation are the same.
An Industry Example of Kappa
The training manager of a large law firm was training staff to proofread legal documents. She decided to try an Attribute Agreement Analysis to see if they would be able to assess the quality of documents on a scale of -2, -1, 0, 1, 2.
Further, she selected 15 documents of varying quality and had them assess each document twice. This allowed a time interval of one week between the two readings to eliminate any bias due to remembering how they rated the document the first time.
The general counsel also rated the documents so they had a standard to measure against for accuracy. Here is a partial representation of the output from the statistical software they used for the analysis and calculations of Kappa.
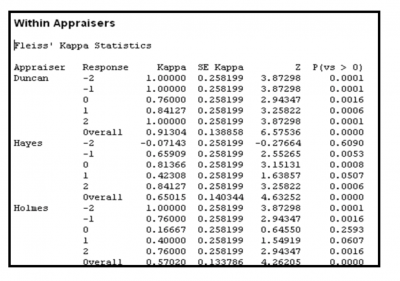
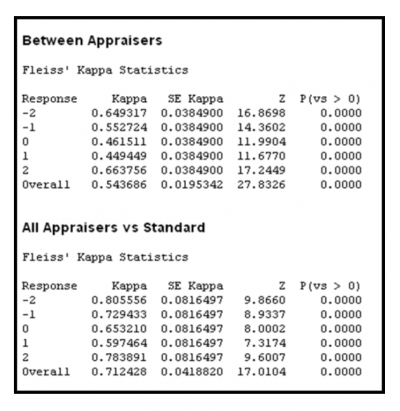
You can see that there is quite a bit of variation in Kappa values for within rater, between rater, and in comparison to the standard.
After reviewing the operational definitions of the scale, they went back and made them clearer so there was no misunderstanding of what each scale value meant. They repeated the analysis, and the Kappa values were now within an acceptable range.
Best Practices
Kappa is the output of doing an Attribute Agreement Analysis. Setting up and executing the technique and testing process will affect your ultimate calculations.
Operational Definitions
When deciding on the attribute you wish to measure, there must be a clear and agreed-upon operational definition to eliminate any variation due to conflicting definitions of what you are measuring. What does “good” mean? What does a 3 mean on a 1 to 5 scale?
Selecting Items for Your Study
Be sure you have representative items in your study for the different conditions of your attribute. If you are measuring things that are good/bad, be sure you have about half and half in your study.
Testing Against a Standard
There are three common characteristics of your measurement system when doing an Attribute Agreement Analysis. These are intra-rater repeatability, inter-rater reproducibility, and agreement with a standard as a measure of accuracy. You can have excellent repeatability but always be wrong. Multiple raters can agree, but they all can be wrong when compared to the standard or expert rating.
Other Useful Tools and Concepts
There’s plenty to learn when it comes to creating a good workflow in your organization. We’ve talked at length about Kappa, but you might do well to learn about Gamma, another complementary calculation for your data.
Additionally, understanding random variation goes hand in hand with what we’ve discussed here today. Random variation is going to arise in anything you’re producing, so learning how to interpret that data will give you the means to succeed.
Conclusion
Kappa is a form of measurement system analysis for attribute data. Multiple raters are used to make judgements on the characteristic of an item whether it be a simple yes/no or a value on an ordinal scale. The subsequent calculation of Kappa summarizes the degree of agreement among the different raters while removing agreement that could occur by pure chance.
The interpretation of Kappa often follows these guidelines:
- <0 No agreement
- 0 – .20 Slight
- .21 – .40 Fair
- .41 – .60 Moderate
- .61 – .80 Substantial
- .81 – 1.0 Perfect