When the Ritz-Carlton Hotel Company won the Malcolm Baldrige National Quality Award for the second time in 1999, companies across many industries began trying to achieve the same level of outstanding customer satisfaction. This was a good thing, of course, as CEOs and executives began incorporating customer satisfaction into their company goals while also communicating to their managers and employees about the importance of making customers happy.
When Six Sigma and other metrics-based systems began to spread through these companies, it became apparent that customer satisfaction needed to be measured using the same type of data-driven rigor that other performance metrics (processing time, defect levels, financials, etc.) used. After all, if customer satisfaction was to be put at the forefront of a company’s improvement efforts, then a sound means for measuring this quality would be required.
Enter the customer satisfaction survey. What better way to measure customer satisfaction than asking the customers themselves? Companies jumped on the survey bandwagon – using mail, phone, email, web and other survey platforms. Point systems were used (e.g., ratings on a 1-to-10 scale) which produced numerical data and allowed for a host of quantitative analyses. The use of the net promoter score (NPS) to gauge customer loyalty became a standard metric. Customer satisfaction could be broken down by business unit, department and individual employee. Satisfaction levels could be monitored over time to determine upward or downward trends; mathematical comparisons could be made between customer segments as well as product or service types. This was a CEO’s dream – and it seemed there was no limit to the customer-produced information that could help transform a company into the “Ritz-Carlton” of its industry.
In reality, there was no limit to the misunderstanding, abuse, wrong interpretations, wasted resources, poor management and employee dissatisfaction that would result from these surveys. Although some companies were savvy enough to understand and properly interpret their survey results, the majority of companies did not. This remains the case today.
What could go wrong with the use of customer satisfaction surveys? After all, surveys are pretty straightforward tools that have likely been used since the times of the Egyptians (pharaoh satisfaction levels with pyramid quality, etc.). Survey data, however, has a lot of potential issues and limitations that makes it different from other “hard” data that companies utilize. It is critical to recognize these issues when interpreting survey results – otherwise what seems like a great source of information can cause a company to do many bad things.
Survey Biases and Limitations
Customer satisfaction surveys are everywhere; customers are bombarded with email and online survey offers from companies who want to know what customers think about their products and services. In the web-based world, results from these electronic surveys can be immediately stored in databases and analyzed in a thousand different ways. In nearly all of these instances, however, the results are wrought with limitations and flaws.  The most common survey problems include types of bias, variations in customer interpretations of scales and lack of statistical significance. These issues must be considered if sound conclusions are to be drawn from survey results.
The most common survey problems include types of bias, variations in customer interpretations of scales and lack of statistical significance. These issues must be considered if sound conclusions are to be drawn from survey results.
Non-response Bias
Anyone who has called a credit card company or bank is likely to have been asked to stay on the line after their call is complete in order to take a customer satisfaction survey. How many people stay on the line to take that survey? The vast majority of people hang up as soon as the call is complete. But what if the service that a customer received on the phone call was terrible and the agent was rude? It is more likely that the customer would stay on the call and complete the survey at the end of the call. And that is a perfect example of the non-response bias at work.
Although surveys are typically offered to a random sample of customers, the recipient’s decision whether or not to respond to the survey is not random. Once a survey response rate dips below 80 percent or so, the inherent non-response bias will begin to affect the results. The lower the response rate, the greater the non-response bias. The reason for this is fairly obvious: the group of people who choose to answer a survey is not necessarily representative of the customer population as a whole. The survey responders are more motivated to take the time to answer the survey than the non-responders; therefore, this group tends to contain a higher proportion of people who have had either very good, or more often, very bad experiences. Changes in response rates will have a significant effect on the survey results. Typically, lower response rates will produce more negative results, even if there is no actual change in the satisfaction level of the population.
Survey Methodology Bias
The manner in which a customer satisfaction survey is administered can also affect the results. Surveys that are administered in person or by phone tend to result in higher scores than identical surveys distributed by email, snail mail or on the Internet. This is due to people’s natural social tendency to be more positive when there is another person directly receiving feedback (even if the recipient is an independent surveyor). Most people do not like to give another individual direct criticism, so responses tend to be more favorable about a product (or service, etc.) when speaking in person or by phone. Email or mail surveys have no direct human interaction and, therefore, the survey taker often feels more freedom to share negative feedback – criticisms are more likely to fly.
In addition, the manner in which a question is asked can have a significant affect on the results. Small changes in wording can affect the apparent tone of a question, which in turn can impact the responses and the overall results. For example, asking “How successful were we at fulfilling your service needs” may produce a different result than “How would you rate our service?” although they are similar questions in essence. Even the process by which a survey is presented to the recipient can alter the results – surveys that are offered as a means of improving products or services to the customer by a “caring” company will yield different outcomes than surveys administered solely as data collection exercises or surveys given out with no explanation at all.
Regional Biases
Another well-known source of bias that exists within many survey results is regional bias. People from different geographical regions, states, countries, urban vs. suburban or rural locations, etc. tend to show systematic differences in their interpretations of point scales and their tendencies to give higher or lower scores. Corporations that have business units across diverse locations have historically misinterpreted their survey results this way. They will assume that a lower score from one business unit indicates lesser performance, when in fact that score may simply reflect a regional bias compared to the locations of other business units.
Variation in Customer Interpretation and Repeatability of the Rating Scale
Imagine that your job is to measure the length of each identical widget that your company produces to make sure that the quality and consistency of your product is satisfactory. But instead of having a single calibrated ruler with which to make all measurements, you must make each measurement with a different ruler. This is not a problem if all the rulers are identical, but you notice that each ruler has its own calibration. What measures as one inch for one ruler measures 1¼ inches for another ruler, ¾ of an inch for a third ruler, etc. How well could you evaluate the consistency of the widget lengths with this measurement system if you need to determine lengths to the nearest 1/16 of an inch? Welcome to the world of customer satisfaction surveys.
Unlike the scale of a ruler or other instrument which remains constant for all measurements (assuming its calibration remains intact), the interpretation of a survey rating scale varies for each responder. In other words, the people who complete the survey have their own “calibrations” for the scale. Some people tend to be more positive in their assessments; other people are inherently more negative. On a scale of 1 to 10, the same level of satisfaction might solicit a 10 from one person but only a 7 or 8 from another.
In addition, most surveys exhibit poor repeatability. When survey recipients are given the exact same survey questions multiple times, there are often differences in their responses. Surveys rarely pass a basic gage R&R (repeatability and reproducibility) assessment. Because of these factors, surveys should be considered noisy (and biased) measurement systems – their results cannot be interpreted with the same precision and discernment as data that is produced by a physical measurement gauge.
Statistical Significance
Surveys are, by their very nature, a statistical undertaking and thus it is essential to take the statistical sampling error into account when interpreting survey data. Sample size is part of the calculation for this sampling error: if a survey result shows a 50 percent satisfaction rating, does that represent 2 positive responses out of 4 surveys or 500 positives out of 1,000 surveys? Clearly the margin of error will be different for those two cases.
There are undoubtedly thousands of examples of companies failing to take margin of error into account when interpreting survey results. A well-known financial institution routinely punished or rewarded its call center personnel based on monthly survey results – a 2 percent drop in customer satisfaction would solicit calls from executives to their managers demanding to know why the performance level of their call center was decreasing. Never mind that the results were calculated from 40 survey results with a corresponding margin of error of ±13 percent, making the 2 percent drop statistically meaningless.
An optical company set up quarterly employee performance bonuses based on individual customer satisfaction scores. By achieving an average score between 4.5 and 4.6 (based on a 1-to-5 scale), an employee would get a minimum bonus; if they achieved an average score between 4.6 and 4.7, they would get an additional bonus; and if their average score was above 4.7, they would receive the maximum possible bonus. As it turned out, each employee’s score was calculated from an average of less than 15 surveys – the margin of error for those average scores was ±0.5. All of the employees had average scores within this margin of error and, thus, there was no distinction between any of the employees. Differences of 0.1 points were purely statistical noise with no basis in actual performance levels.
When companies fail to take margin of error into account, they wind up making decisions, rewarding or punishing people, and taking actions based purely on random chance. As statistician W. Edwards Deming shared 50 years ago, one of the fastest ways to completely discourage people and create an intolerable work environment is to evaluate people based on things that are out of their control.
Proper Use of Surveys
What can be done? Is there a way to extract useful information about surveys without misusing them? Or should customer satisfaction surveys be abandoned as a means of measuring performance?
It is better not to use surveys at all then to misuse and misinterpret them. The harm that can be done when biases and margin of error are not understood is worse than the benefit of having misleading information. If the information from surveys can be properly understood and interpreted within their limitations, however, then surveys can help guide companies in making their customers happy. The following are some ways that can be accomplished.
Determine the Drivers of Customer Satisfaction and Measure Them
Customers generally are not pleased or displeased with companies by chance – there are drivers that influence their level of satisfaction. Use surveys to determine what those key drivers are and then put performance metrics on those drivers, not on the survey results themselves. Ask customers for the reasons why they are satisfied or dissatisfied, then affinitize those responses and put them on a pareto chart. This information will be more valuable than a satisfaction score, as it will identify root causes of customer happiness or unhappiness on which measurements and metrics can then be developed.
For example, if it can be established that responsiveness is a key driver in customer satisfaction then start measuring the time between when a customer contacts the company and when the company responds. That is a hard measurement and is more reliable than a satisfaction score. The more that a company focuses on improving the metrics that are important to the customer, the more likely that company will improve real customer satisfaction (which is not always reflected in biased and small-sample survey results).
Improve Your Response Rate
If survey results should reflect the general customer population (and not a biased subset of customers) then there must be a high response rate to minimize the non-response bias. Again, the goal should be at least an 80-percent response rate. One way to achieve this is to send out fewer surveys but send them to a targeted group that has been contacted ahead of time. Incentives for completing the survey along with reminder messages can help increase the response rate significantly.
Making the surveys short, fast and painless to complete can go a long way toward improving response rates. As tempting as it may be to ask numerous and detailed questions to squeeze every ounce of information possible out of the customer, a company is likely to have survey abandonment when customers realize the survey is going to take longer than a few minutes to complete. A company is better off using a concise survey that is quick and easy for the customers to complete. Ask a few key questions and let the customers move on to whatever else they need to attend to; the company will end up with a higher response rate.
Do Not Make Comparisons When Biases Are Present
A lot of companies use customer survey results to try to score and compare their employees, business units, departments, and so on. These types of comparisons must be taken with a grain of salt, as there are too many potential biases that can produce erroneous results. Do not try to compare across geographic regions (especially across different countries for international companies), as the geographic bias may lead to the wrong conclusions. If the business is a national or international company and wishes to sample across a large customer base, use stratified random sampling so that the customers are sampled in the same geographic proportion that is representative of the general customer population.
Also, do not compare results from surveys that were administered differently (phone versus mail, email, etc.) – even if the survey questions were identical. The survey methodology can have a significant influence on the results. Be sure that the surveys are identical and are administered to customers using the exact same process.
Surveys are rarely capable of passing a basic gage R&R study. They represent a measurement system that is noisy and flawed; using survey results to make fine discernments, therefore, is usually not possible.
Always Account for Statistical Significance in Survey Results
This is the root of the majority of survey abuse – where management makes decisions based on random chance rather than on significant results. In these situations Six Sigma tools can be a significant asset as it is critical to educate management on the importance of proper statistical interpretation of survey results (as with any type of data).
Set a strict rule that no survey result can be presented without including the corresponding margin of error (i.e., the 95 percent confidence intervals). For survey results based on average scores, the margin of error will be roughly
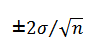
where ? is the standard deviation of the scores and n is the sample size. (Note: For sample sizes <30, the more precise t-distribution formula should be used.) If the survey results are based on percentages rather than average scores, then the margin of error can be expressed as
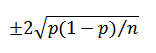
where p is the resulting overall proportion (note that the Clopper-Pearson exact formula should be used if np < 5 or (1-np) < 5). Mandating that a margin of error be included with all survey results helps frame results for management, and will go a long way in getting people to understand the distinction between significant differences and random sampling variation.
Also, be sure to use proper hypothesis testing when making survey result comparisons between groups. Use the following tools as appropriate for the specific scenario:
- For comparing average or median scores, there are t-tests, analysis of variance, or Mood’s Median tests (among others).
- For results based on percentages or counts there are proportions tests or chi-squared analysis.
If comparing a large number of groups or looking for trends that may be occurring over time, the data should be placed on the appropriate control chart. Average scores should be displayed on an X-bar and R, or X-bar and S chart, while scores based on percentages should be shown on a P chart. For surveys with large sample sizes, an I and MR chart may be more appropriate to account for variations in the survey process that are not purely statistical (such as biases changing from sample to sample, which is common). Control charts go a long way in preventing management overreaction to differences or changes that are statistically insignificant.
Finally, make sure that if there goal or targets are being set based on customer satisfaction scores, those target levels must be statistically distinguishable based on margin of error. Otherwise, people are rewarded or punished based purely on chance. In general, it is always better to set goals based on the drivers of customer satisfaction (the hard metrics) rather than on satisfaction scores themselves. Regardless, the goals must be set as statistically significantly different from the current level of performance.
Conclusion
Customer satisfaction surveys are bad, evil things. OK, that’s not necessarily true, but surveys do have a number of pitfalls that can lead to bad decisions, wasted resources and unnecessary angst at a company. The key is to understand survey limitations and to not treat survey data as if it were precise numerical information coming from a sound, calibrated measurement device. The best application of customer surveys is to use them to obtain the drivers of customer happiness or unhappiness, then create the corresponding metrics and track those drivers instead of survey scores. Create simple surveys and strive for high response rates to assure that the customer population is being represented appropriately. Do not use surveys to make comparisons where potential biases may lie, and be sure to include margin of error and proper statistical tools in any analysis of results.
Used properly, customer satisfaction surveys can be valuable tools in helping companies understand their strengths and weaknesses, and in helping to identify areas of emphasis and focus in order to make customers happier. Used improperly, problems ensue. Make sure your company follows the right path.