
Key Points
- Span is a measurement used for non-normal distributions to detect variations.
- You typically truncate your data to make the best use of it.
- You can truncate 5% of the data, or vary it depending on the efficiency of your processes.
Span is a measure of variation in your data. Developed by GE, the span was used when there were outliers or the data distribution was abnormal. Let’s see how it’s calculated and used instead of the range.
What Is Span?
In statistics, it is essential to describe the spread, variation, or dispersion of your data. Excessive variation makes it harder for you to plan and manage your process. The three most common measures of variation are the range, standard deviation, and variance. The range is the measure most similar to span.
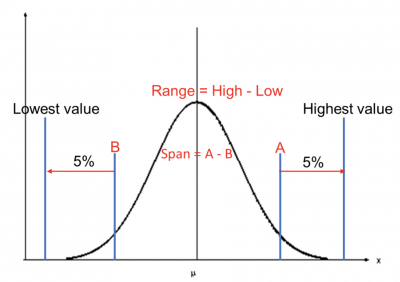
The range is calculated by subtracting the smallest value in your data set from the highest value. The range is always a positive number, with zero being the smallest when the highest and lowest values are the same. Unfortunately, the range can be deceiving if the highest and lowest numbers are extreme outliers or the distribution is non-normal.
To offset that problem, the span is calculated by eliminating some percentage of the data in the tails of the distribution. GE, the developer of the concept, dropped 5% of the data from each tail so other statistical calculations were done using the data between 5% and 95% of the distribution. The trimmed or truncated mean used the span as the basis for a measure of central tendency.
The graph below shows the concept of span versus range.
For an excellent discussion on span and its history, check out this link on isixsigma.com.
An Industry Example of Span
The transportation and delivery manager of a consumer products company was interested in understanding the variation of his customer deliveries. One of his staff had been previously employed at GE and had used the concept of span to measure customer delivery. He helped the manager do the calculations.
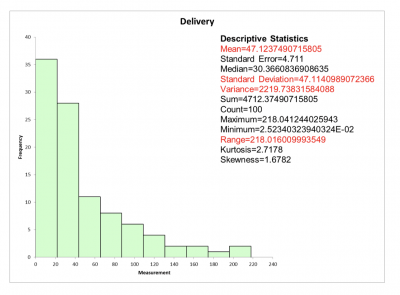
Data was collected on delivery times. As expected, the distribution was skewed, as shown below in the histogram. Note the various traditional calculations for variation highlighted in red.
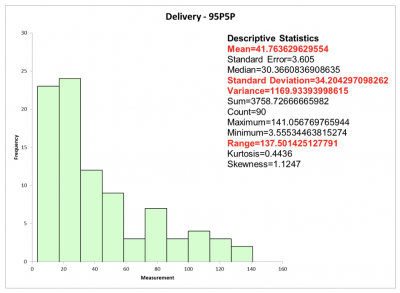
The manager was just as concerned about delivering too early as he was delivering late. Knowing there were some exceptionally early and late deliveries, he decided to redo his calculations and compute span by eliminating the top and bottom 5% of the delivery dates.
See the resulting graph and statistics below. This became his goal for reducing the overall variation of deliveries.
Does It Need to Be 95/5 for the Data?
So, does the span need to conform to the 5/95 paradigm set? Not at all, you can opt for 1/99 or other probabilities if you so choose. It depends more on the stability and efficiency of your processes rather than sticking to a hard and fast rule. If you have stable and predictable processes, you might choose to go for something that better suits your data.
Other Useful Tools and Concepts
Looking for other tips and tricks to aid your business? Knowing how to best utilize trend charts can tell you quite a bit about how your processes are performing. Further, mastery of these tools allows you to forecast potential future events with careful analysis.
Additionally, knowing how to leverage Likert Scales in your surveying can illuminate quite a bit about your customer’s needs. The psychology behind these scales is proven and tested, allowing for granular detail over basic decisions and wants.