
The manufacturing and transactional worlds have long used productivity as a measure of efficiency. Traditionally, a productivity metric has been used for assessing return on investment on machinery to measure the contributions of team members. In the growing service economy where human resources are the biggest driver of costs in the organization, management teams want to get the maximum return from their employees but the “machinery” is not as easily measured. In this DMAIC (Define, Measure, Analyze, Improve, Control) case study, a project was performed to maximize productivity for a business process management (BPM) application support team.
Define
An IT-BPO (information technology-business process outsourcing) organization provided application support services to its global customers. A particular BPM application support team served 16 customers for multiple business processes ranging from account reconciliation to planning and scheduling. To manage these customers, multiple businesses processes and shifts were used to cover normal business hours across the globe – 24 hours per day, 7 days per week. Several staff members were added to the team at the beginning of this client relationship so as not to compromise service levels. Under their client contract however, the IT-BPO company promised to deliver 10 percent increased productivity on a year-over-year basis without influencing service levels.
Measure
As the nature of the IT-BPO’s operation was vastly different from a manufacturing scenario (consider identical widget production in continuous flow), simply measuring productivity was a problem; actually meeting and exceeding productivity levels was a distant dream for the support team. To develop the necessary metrics for this project, the Six Sigma team looked at the classic definition of productivity – the ratio of size of work to effort involved – to develop a comprehensive metric. The challenge was to translate the size of work and to measure the total effort in the support operation.
In an application support scenario, tasks can generally be classified into four broad areas: 1) application monitoring, 2) service request resolution, 3) problem ticket resolution and 4) change requests, enhancements, and research and development (R&D).
The total effort investment could be computed on a daily basis as the number of hours at work (excluding breaks) put in by different consultants of different seniority levels. Roughly speaking, the bulk of the repetitive and menial type of tasks (such as monitoring and service requests) were handled by level 1 (L1) consultants and others requiring more thought and knowledge were shouldered by level 2 (L2) consultants. In order to understand the total size of work on a daily basis and the total effort involved per day, the team developed a utilization metric for L1 and L2 consultants by applying the model shown in Figure 1.
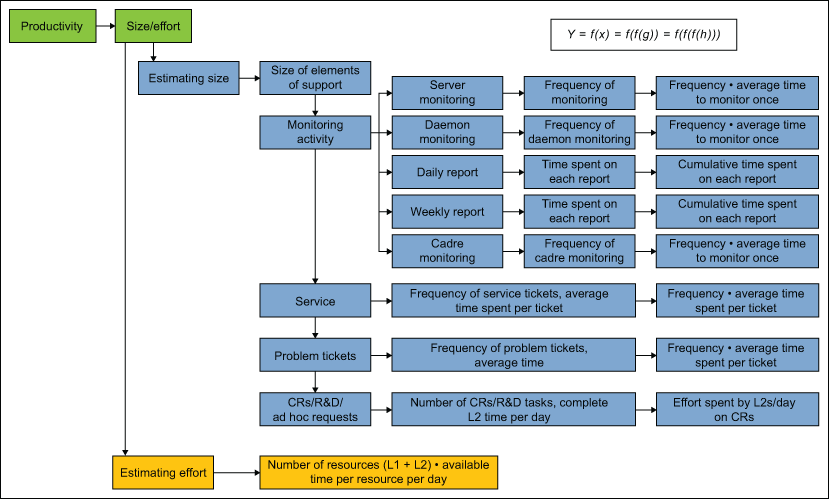
A quantifiable metric for the effort involved for each transaction of problem ticket resolution did not exist so the team started with one based on an estimate by subject matter experts. Then for two successive weeks, a time and motion study was conducted for each customer process to capture the frequency of the defined activities and the average effort involved for performing that activity per day.
During the time and motion study, it became clear that there was no clear boundary between the contributions of L1 and L2 consultants to the resolution of problem tickets and service requests. The contribution level of L1:L2 consultants was observed and tabulated for different customer processes (as shown in Table 1).
The team defined resource utilization as normal if it was within the range of 65 percent to 85 percent. Anything beyond this boundary was categorized as underutilized or overutilized. An overutilized resource would, in this instance, be someone requiring 12 to 14 hours on a given day, rather than the allotted 8 hours, to finish the volume of work they receive. Having gathered the frequency data of an activity’s occurrence in a day and the average time of its performance, the team was able to compute the total effort invested by the team on each individual task. By examining team composition (defined by the number of L1 or L2 consultants and project manager) coupled with activity alignment per consultant type, the team determined the daily activity required for individual L1 and L2 consultants.
| Table 1: Daily Activity for L1 and L2 Consultants (in minutes) | ||||||||
| Activity/Level |
Customer A |
Customer B |
Customer C |
Customer D |
Customer E |
Customer F |
Customer G |
Customer H |
| Number of L1 consultants |
3
|
5 |
3 |
3 |
5 |
5 |
2 |
4 |
| Number of L2 consultants |
1 |
2 |
1 |
2 |
2 |
2 |
1 |
1 |
| Monitoring |
165 |
141 |
193 |
195 |
256 |
223 |
655 |
207 |
| Normal service requests |
23 |
70 |
136 |
183 |
248 |
55 |
340 |
53 |
| Urgent service requests |
3 |
9 |
4 |
30 |
13 |
15 |
34 |
9 |
| Normal problem tickets |
1 |
1 |
1 |
4 |
39 |
6 |
35 |
11 |
| Urgent problem tickets |
0 |
0 |
0 |
0 |
2 |
1 |
2 |
1 |
| Business critical problem tickets |
0 |
0 |
0 |
4 |
3 |
4 |
3 |
15 |
| Ad hoc requests |
30 |
15 |
65 |
15 |
45 |
90 |
105 |
90 |
| Change requests/R&D |
180 |
90 |
180 |
90 |
90 |
90 |
180 |
180 |
| L1 and L2 Shift Utilization* | ||||||||
| L1 consultants |
42% |
47% |
74% |
86% |
120% |
70% |
240% |
64% |
| L2 consultants |
50% |
34% |
75% |
43% |
115% |
58% |
139% |
98% |
|
* Utilization number = sum of all efforts for a customer against L1 or L2 consultant divided by the available effort per shift (480 minutes) Cells highlighted in yellow denote overutilized resources |
||||||||
Analyze
The measurement of resource utilization across different teams assigned to various customer processes established:
- Existence of overutilized and underutilized team bandwidth
- Existence of effort-intensive areas and tasks for overutilized team members
Regularly tracking the utilization metric across the different teams revealed the outliers – those process teams that fell under 65 percent or over 85 percent utilization at L1 or L2. The overutilized teams were selected for further analysis to try to understand why these teams were investing an above average effort in monitoring activities, service request resolutions or problem ticket resolutions. Focused brainstorming sessions were conducted using fishbone analysis to determine the root causes and appropriate corrective actions. One fishbone example is shown in Figure 2.
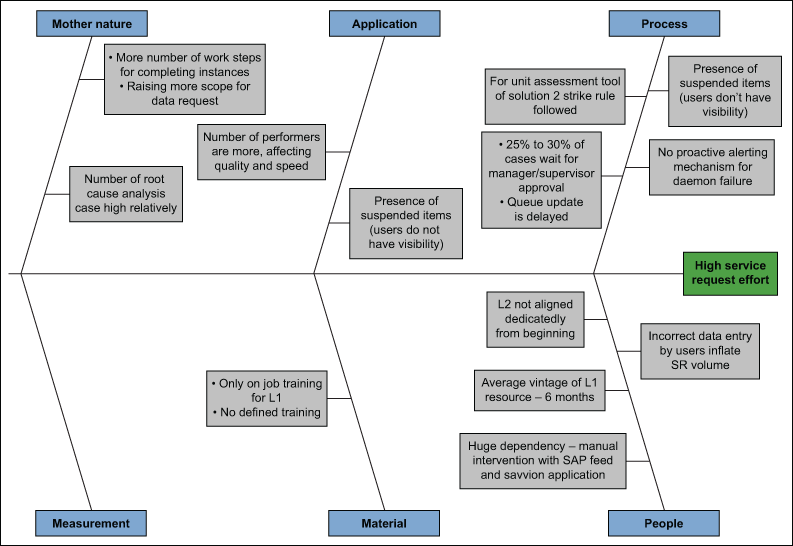
Banking on the collective wisdom of the team, the Six Sigma team gathered improvement action items and prioritized them for execution. As the application support team and its project managers were involved in all of the important decisions of turnaround, the improvement executions were carried out smoothly.
The analysis of the overutilized and underutilized teams showed that the volume of service requests, problem tickets and monitoring efforts were the key drivers of utilization. The challenge was to marry overutilized and underutilized team members in such a way that effort investment was optimized – ideally leading to a reduction in full-time employees. The first roadblock to this idea of merging teams was the challenge presented by team members spread across different geographic locations. The second roadblock was the knowledge management and multiple skillsets that would be needed among different team members so that a consultant could work on more than one customer process.
Improve
The first improvement approach that led to significant changes was the restructuring of the globally located team. The consolidation of resources (people and infrastructure) to one location to manage the majority of customers (except those that were on a customer-dedicated network) made it possible to engage and balance the productivity level of the team. Resources were fielded for optimal productivity levels by addressing all of the factors (total monitoring effort, total volume of service requests, total volume of problem tickets, total volume of change requests and shift coverage). With several weeks of utilization measures available, the team was able to run various what-if scenarios of managing customer processes with different combinations of L1 and L2 consultants. Teams were restructured in a way that saved on the number of staff members while permitting the least possible risk to service delivery performance. To ease the transition to the shared service model, a greater emphasis was given to knowledge management, knowledge transfer and cross-training.
The second improvement approach helped reduce the high-effort area of specific customer processes. Those customer-facing teams that were getting large numbers of service requests and problem tickets, and investing significant manual effort in monitoring activities, were constantly encouraged to identify ways to reduce effort. Brainstorming that was performed in the Analyze phase had led to a number of improvement action points. One sample root cause corrective action list for a specific customer process is shown in Table 2.
| Table 2: Sample Root Cause Corrective Action List | ||
| Variation Sources | Control-impact rating* | Improvement Action Items |
| Presence of suspended items (users do not have visibility) | H-H | Code level verification pointed to key areas that cause suspended items |
| No proactive alerting mechanism for Daemon failure | H-H | Middleware to create log and be sent every hour to support team |
|
M-H | Users and managers to receive notification for every case raised that require approval |
| Incorrect data entry by users inflates service request volume | M-H | Mandatory and optional field dropdown values instead of free text |
| No dedicated L2 consultant aligned to customer-specific process | L-H | L2 to handhold L1s until the process stabilizes |
|
M-H | Training manual preparation and formal training boot camp for L1s |
| A higher number of work steps for completing tasks leads to more data requests | M-H | To be taken with business requirement |
| Number of root cause analysis cases is relatively higher | M-H | Dedicated L2 consultant to coordinate with development team |
| * L: low, M: medium, H: high | ||
Control
The improvement measures taken in the Improve phase led to wonderful results. The team reduced the number of service requests, the problem tickets volume and the monitoring effort required on a daily basis.
The next challenge before the team was to sustain the gains made. Now that they had started monitoring team utilization at L1 and L2, they institutionalized time sheet entry by team members. Time sheet data was used in conjunction with control chart analysis of the utilization metric on a weekly basis. Whenever the chart showed out-of-control data, the team lead would inform stakeholders and take appropriate actions.
In addition, aware of the major task buckets of the support team, team leads started monitoring the daily average inflow volume of service requests and problem tickets. The ticketing system data was leveraged in a macro-enabled spreadsheet for control chart analysis on a fortnightly basis for each customer process or combination of customer processes. These control charts and dashboards were integrated with fortnightly management meetings to discuss challenges, provide required help and plan future actions.
The project was able to create capacity without significant capital expenditure. This was achieved through a two-pronged strategy:
- Load balancing: Making sure all team members were equally and evenly utilized. Before the project, a few teams were overutilized with the magnitude of work they had and a few were underutilized for want of work. A shared services facility enabled load balancing.
- Lean Six Sigma application: High-effort, intensive customer processes were reduced by automating some high-frequency manual process steps, solving frequently encountered problems and actively sharing knowledge. Once the magnitude of work was reduced in the overutilized teams, the utilization metric started to trend down, going from 240 percent to below 90 percent.
This Six Sigma project saved the equivalent of more than 10 full-time employees. With those saved costs, the company was able to add new customer processes in subsequent years.