
“Why?” It’s a question that Lean Six Sigma (LSS) practitioners know well. It’s the provocation that has led to transformations across industries. And, when it comes to machine learning solutions, it’s the prompt that has been to both the benefit and to the detriment of implementing them into operations.
A Trend with Challenges
Artificial intelligence (AI) and machine learning (ML) are not new concepts. The use of computer algorithms to achieve a particular goal while simultaneously improving themselves has been explored since the mid-1900s.
Although glorified concepts and creative applications of AI/ML principles permeate history, it wasn’t until the late 2010s that the application of machine learning in operations (MLOps) gained traction,1 and industry professionals collaborated with AI/ML experts to pilot and scale solutions to address gaps in business performance. Corporate objectives – such as increasing demand forecast accuracy, manufacturing self-driving vehicles and evaluating company financials to improve EBITDA (earnings before interest, taxes, depreciation and amortization) performance – have all seen significant progress in recent years as a result of AI/ML.
With so many applications wherein AI/ML solutions can drive business transformation, how does the question of “Why?” become such a detractor from the success of ML models within operations? As it turns out, one of the most persistent problems that plague ML solutions is model “explainability.” Within a production environment, if we are unable to explain the output of a model (a situation often called black box ML), how do we know what inputs or variables serve as the root cause of a problem? How do we determine our why?
What’s Your Tradeoff?
The question presents an interesting value proposition for LSS professionals and businesses. Do you sacrifice model performance, such as accuracy or speed, for the ability to explain a model result? Or do you forego the visibility into the drivers of a particular output in exchange for an assumed increase in model performance?
As an example, when building an ML-based model to predict demand for a particular product, which solution offers the greatest value to the business:
- A model that may not provide the highest forecast accuracy as possible but still provides a thorough understanding into model inputs that allows stakeholders to quickly course-correct any ill-performing components of the model, or
- A model that theoretically maximizes forecast accuracy but leaves the business blind to immediate actions it can take to rectify any issues for which the model output is responsible?
One could justifiably argue that the choice is a riddle of sorts; however, from an LSS standpoint, the answer is simple: the strategic direction should be to gravitate toward explainable models.
MLOps Through a Continuous Improvement Lens
When we understand the why behind operational challenges, we position ourselves to best maneuver unanticipated, adverse effects coming as a result of a strategic decision, scaled solution or some variable that went unaccounted for. This sets the foundation for every continuous improvement analysis – taking the why and enhancing the value stream to mitigate (or eliminate) the unfavorable impacts that are attributed to the why.
As practitioners of continuous improvement, if pressing toward an explainable model is the guidance, how do we develop a solution that introduces a new capability into business operations while still maintaining the necessary insight we need – insight into the why – to enable continued transformation? The answer is the same as it has always been – by starting with the problem.
Once we know the problem, we can begin the discovery phase of identifying and mapping the end-to-end value stream of the issue we are searching to resolve. This is where every transformation should begin as it will provide clarity to the why behind questions such as:
- What is the motivating key performance indicator (KPI)?
- What technologies exist and, more importantly, what technologies are appropriate to solve this specific challenge?
- How will the technology be applied?
For example, when defining various countermeasures to address the business challenge of decreasing, or at least smoothing, erratic overtime labor spend that is currently required to support operations, two intuitive solutions could be to:
- Use robotic process automation (RPA) to automate manual activities performed, or
- Leverage ML to forecast processing volume to help optimally plan the labor need.
In the scenario above, the driving KPI is labor spend and the two technologies that could be appropriately applied are RPA and ML. What’s more, we’ve mapped a method for how the technologies are to be used depending on which solution is preferred.
Data: The Achilles’ Heel of AI and ML
Identifying the problem and mapping the current-state way of working also sets the foundation for the lifeline of all ML models – data. No ML initiative can be successful without data. As an extension, having the right data makes all the difference.
Take for example the situation in which a model exhibited racial bias and discrimination against African Americans when it came to receiving healthcare services2 or the model that demonstrated a gender bias when determining lines of credit for the Apple Card.3 An added example would be an AI model that threatens equal employment opportunity by disqualifying older applicants, those who may suffer from depression or career hopefuls who are on the autism spectrum.4 While the bases of these models may have been ethical and honorable, the data used to build and train the models resulted in outputs that came under public scrutiny when placed in operations.
Because end results have the potential to be so far removed from their anticipated purpose, it is of critical importance to understand the as-is data landscape in preparation for the to-be data ecosystem.
- What is the problem we are looking solve?
- How does data tie into the process?
- What datasets are we using?
- How is the data used?
- How does the data influence the output?
- What message is the data communicating?
The list goes on but questions like these are the data-related queries that will help facilitate an understanding of the current-state process and identify data gaps that will need to be addressed in the ideal, transformed future-state process. Getting to this level of detail is all the more critical when you think about how data-preparation and data-wrangling activities will consume an estimated 80 percent the time dedicated to an AI/ML project.
After performing the gap analysis between the current state and target condition, there should be clear line of sight to the menu of datasets required to elevate operational performance – the datasets that will allow us to understand why a model performs the way it does.
Model Consumption: A Visual Factory for MLOps
Dashboards and visual reporting tools are all but necessary components to the visual factory – the same can be said for ML solutions purposed for operations. If information from the model isn’t presented in a form that can be easily digested to generate actionable business processes, operational implementation of the AI/ML solution is destined to fail.
Consider a quick example of the visual factory from a traditional LSS perspective. A graphical display of green, yellow or red may indicate whether a piece of equipment is functioning optimally, is in need of preventative maintenance or has reached critical failure, respectively. To that end, depending on the visual cue, a certain business process may follow – whether it’s performing the necessary maintenance or replacing the equipment altogether. Regarding AI/ML solutions, though, if the customer of the model does not have any indication as to whether the output is acceptable or not, the solution falls short of its fundamental objective: to deliver a true business transformation.
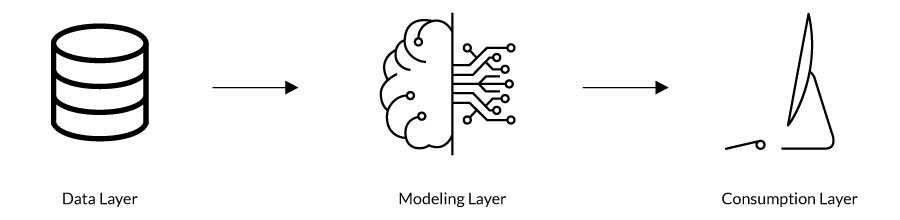
The consumption layer, the component of ML-based solutions that visually depicts an output, is the third and final piece to an AI/ML solution, which is also comprised of a data layer (where data is structured and stored) and a modeling layer (where the model code exists), as shown in the figure below.
The consumption layer is the aspect of the solution that equips process owners with the information essential to effectively managing business processes in transformed state, to take a prescribed action against a particular output. The data layer represents pulling raw data form data sources and performing ETL (extract, transfer, load) processes into landing zones. The modeling layer is the component of the solution that applies logic and business rules to data before it is passed to the consumption layer – where model outputs are presented in visual dashboards for business process management.
The consumption layer can manifest itself through several various mediums. This can be as simple as a spreadsheet-based report and chart, or a more complex dashboard built using a data visualization tool such as Tableau of Microsoft Power BI. In either case, though, the visual output is accompanied by a standardized business process to execute as conditions dictate.
A Welcome Addition to the LSS Toolkit
At a time when corporations are focused on creating new ways of working and generating new capabilities to elevate their business models,5 business transformation sets the stage for a new landscape to apply continuous improvement principles. Who better to lead these breakthrough initiatives other than LSS professionals?
If you were to ask me if I am a data scientist or if I am well-versed in Python (programming language), I would answer with a clear and definitive “No.” The next question to follow may naturally be then, why is it that I am tasked with leading or consulting on a multitude of AI and ML projects? It’s because, outside of possessing a strong (and growing) understanding of the capabilities of various “exponential technologies,” I start with why.
Starting with why allows you to define the problem in the simplest form possible – a crucial measure when dealing with already complex business challenges and technologies. The why will help you understand the full value stream of the operational process and how the appropriate technology may apply – a necessary step when performing the gap analysis and designing the ideal future state.
A why will shape the business requirements of an output needed to act on model results – a mandatory component of the solution before deploying a model.
Your why can be the strongest tool you have in successfully implementing an AI/ML solution into operations to deliver a business transformation.
References
1. Deloitte. “Technology, Media and Telecommunications Predictions,” 2018. https://www2.deloitte.com/content/dam/Deloitte/global/Images/infographics/technologymediatelecommunications/gx-deloitte-tmt-2018-predictions-full-report.pdf. Accessed September 13, 2020.
2. Khan, Amina. “When computers make biased health decisions, black patients pay the price, study says,” Los Angeles Times, October 24, 2019. https://www.latimes.com/science/story/2019-10-24/computer-algorithm-fuels-racial-bias-in-us-healthcare. Accessed September 13, 2020.
3. ODSC – Open Data Science. “Apple Pay Card’s Credit Determining AI: Gender Biased?” Medium. November 18, 2019. https://medium.com/@ODSC/apple-pay-cards-credit-determining-ai-gender-biased-7b3c03f7ac81. Accessed September 13, 2020.
4. Barnes, Patricia. “Artificial Intelligence Poses New Threat to Equal Employment Opportunity,” Forbes. November 10, 2019. https://www.forbes.com/sites/patriciagbarnes/2019/11/10/artificial-intelligence-poses-new-threat-to-equal-employment-opportunity/#9f31f4364888. Accessed September 13, 2020.
5. McKinsey and Company. “Artificial Intelligence: The Next Digital Frontier?” June 2017. https://www.mckinsey.com/~/media/McKinsey/Industries/Advanced%20Electronics/Our%20Insights/
How%20artificial%20intelligence%20can%20deliver%20real%20value%20to%20companies/MGI-Artificial-Intelligence-Discussion-paper.ashx. Accessed September 13, 2020.