
One of the biggest challenges in making improvements in transactional processes is getting data which can be relied upon.
There is an abundance of categorical data in transactional areas – situations where a judgment call is required: Is something right or wrong? Is the application complete? What type of error was made on the request form? Six Sigma project teams often use whatever data they can gather on issues like these without questioning its reliability. That is a mistake.
An often-overlooked tool in the Lean Six Sigma toolbox, gage R&R, can help improve data reliability. It is a method for checking the reproducibility of a measurement system (how closely data from different data collectors match) and repeatability (the likelihood that measurements taken by the same person at different times will match). Gage R&R has been more commonly applied to evaluate continuous data gathering with a measurement instrument of some sort, but the basic approach works extremely well for “judgment call data” in financial services.
Here are two examples which provide insight into using gage R&R.
Case 1: Validating General Ledgers
A Black Belt at a global manufacturing and service company was assigned a project to streamline and reduce the cycle time for validating general ledger accounts. As is typical of these situations, about eight auditors were involved in reviewing the accounts and making two critical judgment calls: 1) Was the ledger prepared correctly? 2) If not, what was wrong with it?
Well-trained in Six Sigma, this Black Belt knew that she could not proceed very far into the project unless she had confidence in the data. So one of her first steps was to perform a gage R&R test. The Black Belt first had an expert auditor review 10 accounts to establish the “master” values for each ledger. (Was it accurate? If not, in what way was it wrong?)
She then had four auditors from the department also review the accounts using their standard procedures. These reviews were compared against the master and scored accordingly. (Did the person reach the right decision about pass/fail? And if it failed, did he or she give the correct reason why.) Two weeks later, she repeated the scoring exercise using the same four auditors and same 10 ledgers. This would allow her to gauge repeatability. The results were surprising:
Repeatability was only 50 to 60 percent. That meant almost half the time each auditor got a different result when they scored the same ledger two weeks apart.
Reproducibility was 40 to 70 percent. In almost a third of the cases, the auditors did not agree with each other.
Acceptable levels of these figures vary depending on situation, but in this case the target was 80 to 90 percent. Obviously this group had some work to do. Based on her experience with “judgment call data,” the Black Belt knew that the root cause was likely in the operational definitions used to make decisions. When the auditors looked at the operational definitions, they realized this was definitely the case. The definitions of what constituted acceptable ledgers, and what constituted an “error” were so vague that it was no wonder people interpreted them differently.
In measurement systems involving discrete (categorical) data, the goal is to have operational definitions that allow any item to be put into one, and only one, category. There cannot be any overlap between categories, and it must be clear how to decide what category something goes into. In this case, the Black Belt helped the team of auditors refine the definitions of various accounting mistakes. They then repeated the gage R&R exercise and scored numbers well over 80 percent.
Case 2: Classifying Calls to a Call Center
Call centers are probably one of the most data-rich environments in any company. Most calls centers already track data like the duration and reason for the call. The Black Belt working in a call center for one company thought he had a leg up on his project because he could quickly construct a Pareto chart on “reason for the call” based on existing data. Surely that meant he could skip the Measure phase of DMAIC (Define, Measure, Analyze, Improve, Control) and go right into examining the reasons for the largest bars on the Pareto.
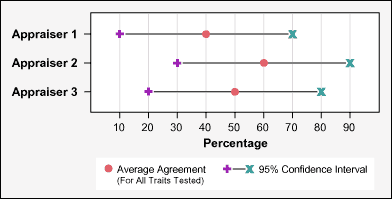
Fortunately, a Master Black Belt suggested he step back and do a gage R&R study on classification of calls before proceeding. So he selected a few of the people responsible for reviewing calls. (These call appraisers are the reason for the recorded message, “This call may be monitored….”) The Black Belt had the call raters review a set of taped calls and evaluate whether the phone operator classified it correctly. That is, whether the call was forwarded to the right group. The exercise was repeated with the same call appraisers a few weeks later.
Much to the Black Belt’s shock, the gage scores showed only 40 to 60 percent repeatability. That meant the raters changed their decisions about the half the time. The adjacent figure illustrates the problem. Reproducibility had similarly low ratings. (The call appraisers did not agree with each other, either.) By implication, that meant that all the historical data on “call classification” was useless from a DMAIC viewpoint.
To fix the situation, the Black Belt followed the same approach as the Six Sigma practitioner in Case 1. He got the raters to discuss the definitions they used to classify calls, refine and rewrite them. Then he ran the tests again. Though the gage R&R scores did improve in the second round, they were still unacceptably low. So the process was repeated and the definitions were revised again. Finally the gage scores rose to acceptable levels.
Conclusion: Lessons About Gage R&R
The Black Belts in both of these companies learned a valuable lesson – never assume that a set of data can be relied upon unless it is proved to be trustworthy. Trying to calibrate what is essentially expert judgment can be tricky. The auditors in the first company, for example, were initially quite resistant to the proposed exercise. After all, what could someone who had never taken an accounting class tell them about auditing? But a strong project sponsor said, “We’re going to do this.” And it got done. Once they saw the results, the auditors’ professional instincts kicked in and they worked well together to discuss their differences and develop improved definitions.
Another Six Sigma tool, measurement systems analysis, provides more complicated techniques to evaluate the reliability of data. But as the cases cited here show, relatively simple experiments where people compare their decisions can work well. This technique can be used easily by Green Belts or Black Belts.
Belts and other Six Sigma project team members also need to remember that evaluating data is a process, not a single event. Measurement systems tend to degrade over time. Thus it is important to regularly assess measurement systems to validate that they continue to provide reliable data – whether those systems are people’s judgment calls or measuring instruments.